React redux 核心概念理解与架构
前言
近期在学习 React 技术,使用React 技术来开发项目,一开始学习觉得学习React并不难,但是慢慢发觉React 已经形成了一个生态系统,很多知识点 和 架框还是比较崎岖的, 比如 React-router 和 React-Redux等 . 其实都是React 全家桶里面的技术,学会后你就会发觉效率突然高起来,使用起来就非常之顺手,不过学习起来还是有点难度的,就Redux而言,对我的学习难度还是很大的,学习了一周,看了大量的文档,做了各种的的DEMO例子,还是不理解其中Redux 各 action reducer store 的核心概念,直到预到其中几篇文章才恍然大悟,文末附上连接 以下总结一下自己的理解与认识:
Reduce
Redux 是一个用来管理JavaScript应用中 data-state(数据状态)和UI-state(UI状态)的工具,对于那些随着时间推移状态管理变得越来越复杂的单页面应用(SPAs)它是比较理想的,同时,它又是和框架无关的,因此,尽管它是提供给React使用,而且和React 完美贴合使用,但它也可以结合Angular 或者 jQuery来使用,作者不想受限于React 而想把它自己的产品放到更大的领域去发展。当然如果是在react 中使用的话,是使用 react-redux.
正如我们前面的教程所提到的,React 在组件之间流通数据.更确切的说,这被叫做“单向数据流”——数据沿着一个方向从父组件流到子组件。由于这个特性,对于没有父子关系的两个组件之间的数据交流就变得不是那么显而易见。
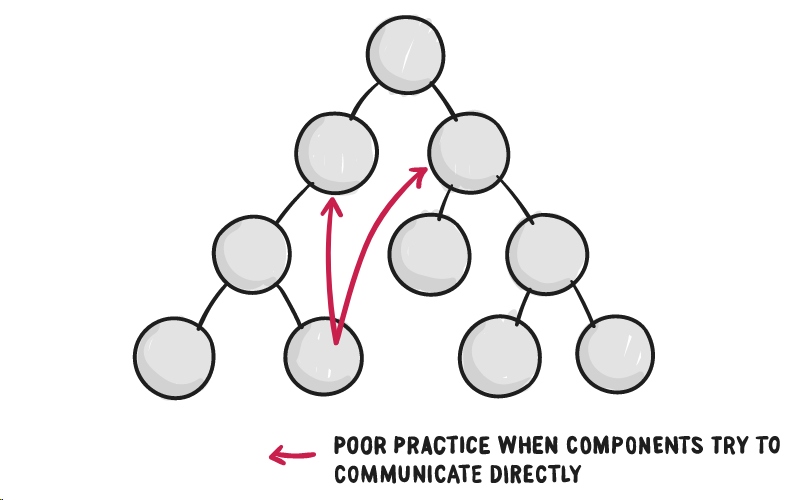
React 不推荐组件对组件直接交流的这种方式,尽管它确实有一些特征可以支持这个方法,但在许多组件之间进行直接的组件对组件的交流被认为是不好的做法,因为这样会容易出错,并且导致spaghetti code —— 过时的代码, 很难维护。
React 提供了一个建议,但是他们希望你能自己来实现它。这里是React官方文档里的一段话:
想让两个没有父子关系的组件进行交流,你可以通过设置你自己的全局事件机制…… Flux 模式就是其中一个可行的方案
这里 Redux 就排上用场了。Redux提供了一个解决方案,通过将应用程序所有的状态都存储在一个地方,叫做“store”。然后组件就可以“dispatch”状态的改变给这个store,而不是直接跟另外的组件交流。所有的组件都应该意识到状态的改变可以“subscribe”给store。
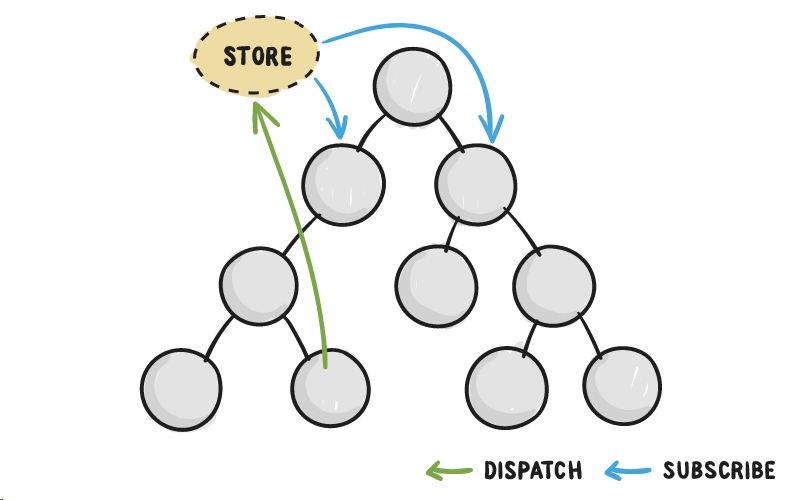
可以把store想象成是应用程序中所有状态改变的中介。随着Redux的介入,所有的组件不再相互直接交流,而是所有的状态改变必须通过store这个单一的真实来源。
这和那些应用程序中不同的部分直接交流的策略有很大的不同。有时,那些策略被认为是容易出错和混乱的原因:
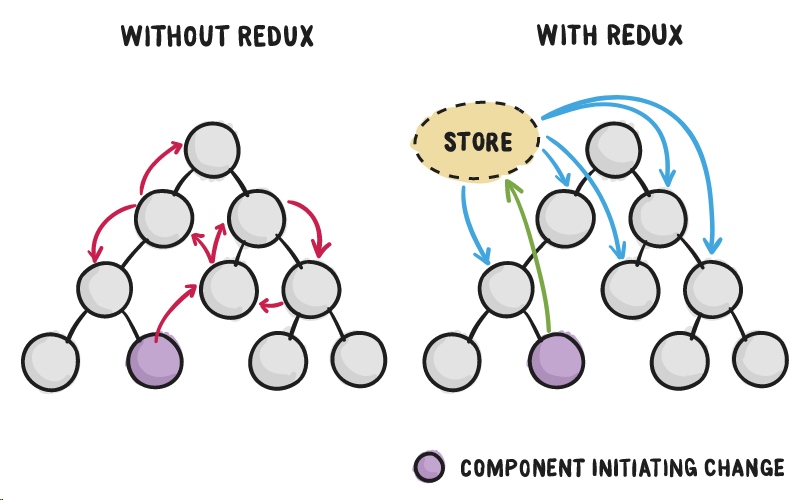
有了Redux,所有的组件都从store中来获取他们的状态,变得非常清晰。同样,组件状态的改变都发送给了store,也很清晰。组件初始化状态的改变只需要关心如何派发给store,而不用去关心一系列其它的组件是否需要状态的改变。这就是Redux如何使数据流变得更简单的原因。
使用store来协调应用之间状态改变的概念就是Flux模式。它是一种倾向单向数据流(比如 React)的设计模式。Redux像Flux,但是他们又有多少关系呢?
Redux is “Flux-like”
Flux 是一种模式,不像Redux那样是可以下载的工具,Redux 是受Flux模式,此外,它比较像Elm。这里有许多有关于Redux和Flux之间比较的指南。它们中的大多数都会得出Redux就是Flux,或者Redux和Flux比较类似的结论,这取决于给Flux定义的规则到底有多严格。然而说到底,这些都无关紧要。Facebook 非常喜欢并且支持Redux,这从它们雇佣了Redux的主要开发者 Dan Abramov 就可以看出。
这篇文章假设你一点都不熟悉Flux的设计模式。不过如果你熟悉,你会注意到许多微小的不同,尤其考虑到Redux的三大指导原则:
1. 单一真实源
Redux只使用一个store来处理应用的状态。因为所有的状态都驻留在同一个地方,Redux称这个为单一真实源。
store中数据的结构完全取决于你,但通常都是针对应用的一个深层嵌套的对象。
Redux的单一store方法是区分Flux多个store方法的最主要区别。
2. 状态是只读的
Redux的文档指出,唯一改变状态的方法就是发出一个action,一个用来描述发生了什么的对象。
这意味着应用不能直接改变状态,相反,“actions” 被派发给store,用来描述一个改变状态的意图。
store对象自己有几个小型的API,对应4个方法:
- store.dispatch(action)
- store.subscribe(listener)
- store.getState()
- replaceReducer(nextReducer)
所以你可以看到,这里没有设置状态的方法。因此,派发一个action是处理应用状态更改的唯一办法。
1 | var action = { |
dispatch() 方法发送了一个对象给Redux,这个对象就被叫做action。这个action可以被描述成一个携带了一个 type 属性以及其它可以被用来更新状态的数据(在这个例子里就是user)的有效负载。记住,在 type 属性之后,这个action对象的设计完全取决于你。
3. 所有的状态改变使用的都是纯函数
就像刚才所描述的,Redux不允许应用直接改变状态,而是用被分派的action来“描述”状态改变或者改变状态的意图。而一个个Reducer就是你自己写的函数,用来处理分派的action,事实上是它真正改变了状态。
一个reducer接受当前的状态(state)作为参数,而且必须返回一个新的状态才能改变之前的状态。1
2
3
4
5// Reducer Function
var someReducer = function(state, action) {
...
return state;
}
reducer 必须使用 “纯”函数 , 一个可以用以下这些特征来描述的术语:
- 没有任何的网络或数据库请求操作
- 返回的值仅依赖于参数
- 参数必须是“不可改变的”,以为着它们将不能被更改。
- 调用具有相同参数集的纯函数将始终返回相同的值
它们被称为“纯”函数是因为它们什么都不做仅仅返回一个基于参数的值。它们在系统的任何其他部分都没有副作用。
redux 工作流程示意图
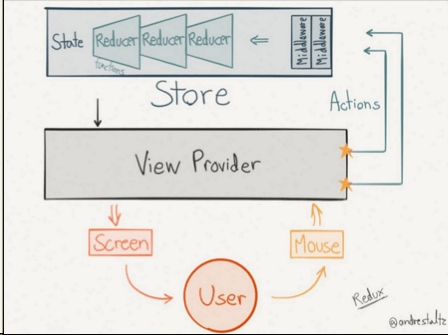
大家可以通过这张流程图发现,在redux(flux单向数据流)中用户的操作并不会直接导致view层的更新,而是view层发出actions通知出发store里的reducer从而来更新state;state的改变会将更新反馈给我们的view层,从而让我们的view层发生相应的反应给用户。
而里面两个重要模块,action 以及 reducer又是什么呢?
action
为什么要有 action ?
每个 web 应用都至少对应一个数据结构,而导致这个数据结构状态更新的来源很丰富;光是用户对 view 的操作(dom 事件)就有几十种,此外还有 ajax 获取数据、路由/hash状态变化的记录和跟踪等。
来源丰富不是最可怕的,更可怕的是每个来源提供的数据结构并不统一。DOM 事件还好,前端可以自主控制与设计; ajax 获取的数据,其结构常常是服务端开发人员说了算,他们面对的业务场景跟前端并不相同,他们往往会为了自己的便利,给出在前端看来很随意的数据结构。
即便是最专业的服务端开发人员,给出最精准的 restful 数据,它也会包含 meta 数据,表明此次返回是否存在错误,如果存在错误,则提供错误信息。除非是 facebook 最近提出的 graphql + relay 模式,不然我们总得对各个来源的数据做一个前期处理。
我们得用专门的处理函数,在各个数据来源里筛选出我们真正需要的数据,不把那些无关紧要的、甚至是脏的数据污染了我们的全局数据对象。
这种对数据来源做萃取工作的函数,就叫 action。它叫这个名字,不是因为它「数据预处理」的功能,而是在 web 应用中所有的数据与状态的变化,几乎都来自「事件」。dom 事件,ajax 成功或失败事件,路由 change 事件, setTimeout 定时器事件,以及自定义事件。任意事件都可能产生需要合并到全局数据对象里的新数据或者线索。
action 跟 event (事件)并不等同。比如在表单的 keyup 事件中,我们只在 e.keyCode 等于回车键或者取消键时,才触发一类 action。dom 事件提供的数据是 event 对象,里面主要包含跟 dom 相关的数据,我们无法直接合并到全局数据对象里,我们只将感兴趣的部分传入 action 函数而已。
所以,是 event 响应函数里主动调用了 action 函数,并且传入它需要的数据。
react给我们提供了一个virtual DOM(一个虚拟DOM对象,也是react之所以在性能上优越的一个重要的点),那么作为一个web应用至少需要又一个数据结构,来让整个应用的数据结构状态更新的来源更加丰富。如果我们将我们的reducer比作我们最终对于数据处理的功能模块,那么action就是对于我们获取到的数据的时的一个预处理功能模块。在我们的web应用中,所有的数据与状态的变化几乎都来源于事件,任何的事件都可能产生需要合并到全局数据对象里的新数据或者线索。但是action与event并不等同,因为并不会所有的event都会出发action,而我们只需要将我们感兴趣的部分传入action函数即可。
action在上面介绍到,仅仅是作为与处理模块,将脏数据筛选掉,它未必产生了可以直接合并到全局对象的数据与结构,它甚至可能只是提供了线索,表示「需要获取某某数据,但不在我这儿」。action 函数的设计,也为它「只提供线索」的做法提供了支持,action 函数必须返回一个带有 type 属性的 plain object。
1 | //actions.js |
如上所示,action 函数的设计理念如下:
- action 的参数用来筛掉脏数据,调用 action 函数的人,有义务只传入它需要的数据
- action 返回的 plain object 中包含属性为 type 的常量值
- 表明这个对象里携带的其他数据应该被如何「再处理」
- 或者不带其他数据,仅仅启示已有数据需要如何调整,或者需要主动获取哪些数据
reducer
为什么要有 reducer ?
action 仅仅是预处理,将脏数据筛选掉,它未必产生了可以直接合并到全局对象的数据与结构,它甚至可能只是提供了线索,表示「需要获取某某数据,但不在我这儿」。action 函数的设计,也为它「只提供线索」的做法提供了支持,action 函数必须返回一个带有 type 属性的 plain object。
reducer 就是迎接 action 函数返回的线索的「数据再处理函数」, action 是「预处理函数」,其实reducer就像一个漏斗一样把各事件与方法都细分到各个事件当中 脏的数据就交由其它方法处理,自己就过滤。
因为 action 返回的数据有个固定的结构,所以 reducer 函数也有个固定结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14//reducer 接受两个参数,全局数据对象 state 以及 action 函数返回的 action 对象
//返回新的全局数据对象 new state
export default (state, action) => {
switch (action.type) {
case A:
return handleA(state)
case B:
return handleB(state)
case C:
return handleC(state)
default:
return state //如果没有匹配上就直接返回原 state
}
}
如上所示,每个 action.type 的 case (A/B/C),都有一个专门对应的数据处理函数 (handleA/handleB/handleC),处理完之后返回新的 state 即可。
reducer 只是一个模式匹配的东西,真正处理数据的函数,是额外在别的地方写的,在 reducer 中调用罢了。
reducer 为什么叫 reducer 呢?因为 action 对象各种各样,每种对应某个 case ,但最后都汇总到 state 对象中,从多到一,这是一个减少( reduce )的过程,所以完成这个过程的函数叫 reducer。
附带参考系列文章:
React 升级:Redux Coocier译 地址
深入到源码:解读 redux 的设计思路与用法 Jade 地址
Redux 入门教程(一):基本用法 阮一峰 地址
Redux 入门教程(二):中间件与异步操作 阮一峰 地址
Redux 入门教程(三):React-Redux 的用法 阮一峰 地址
redux 中action以及reducer的初步介绍 UED 地址

